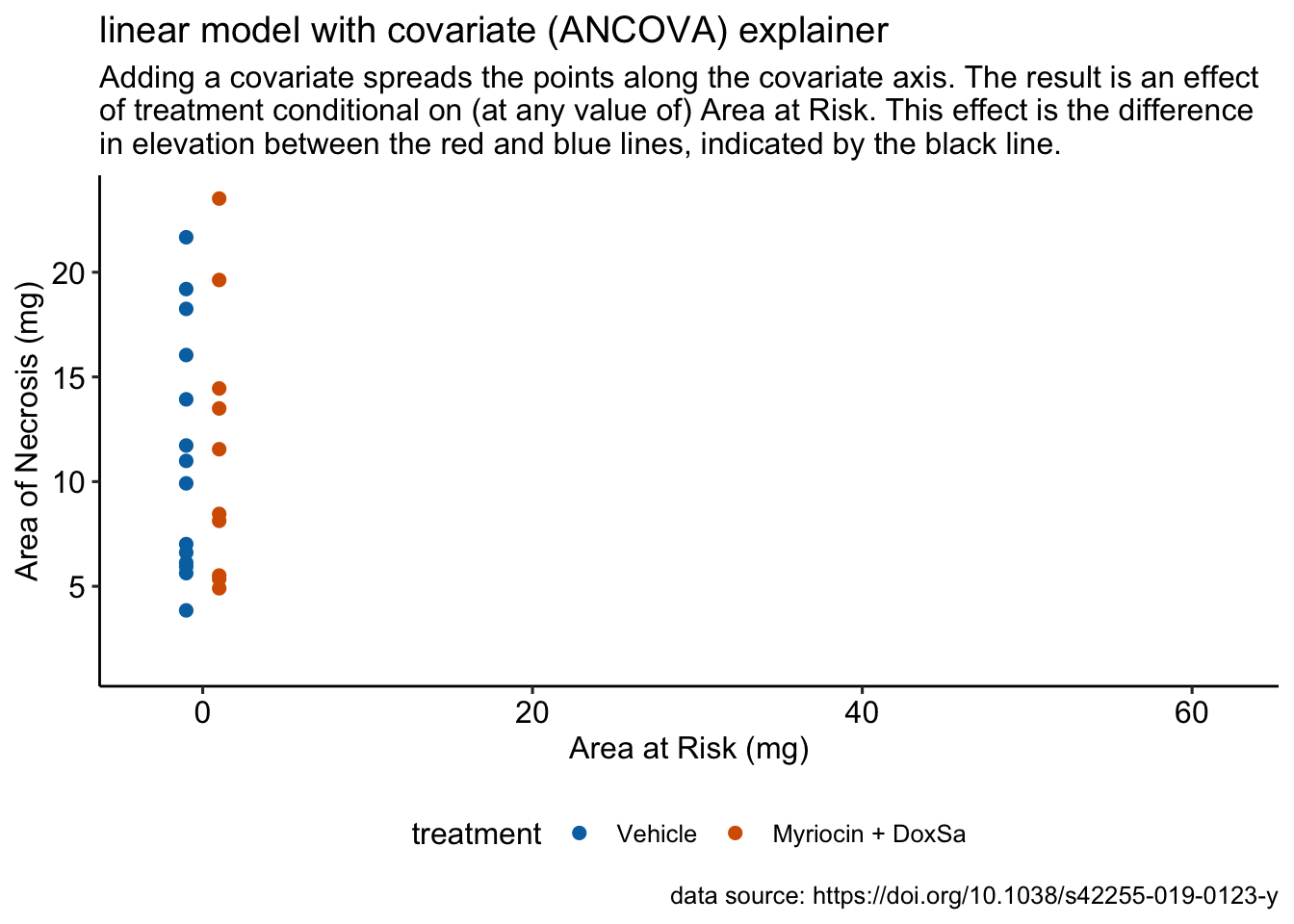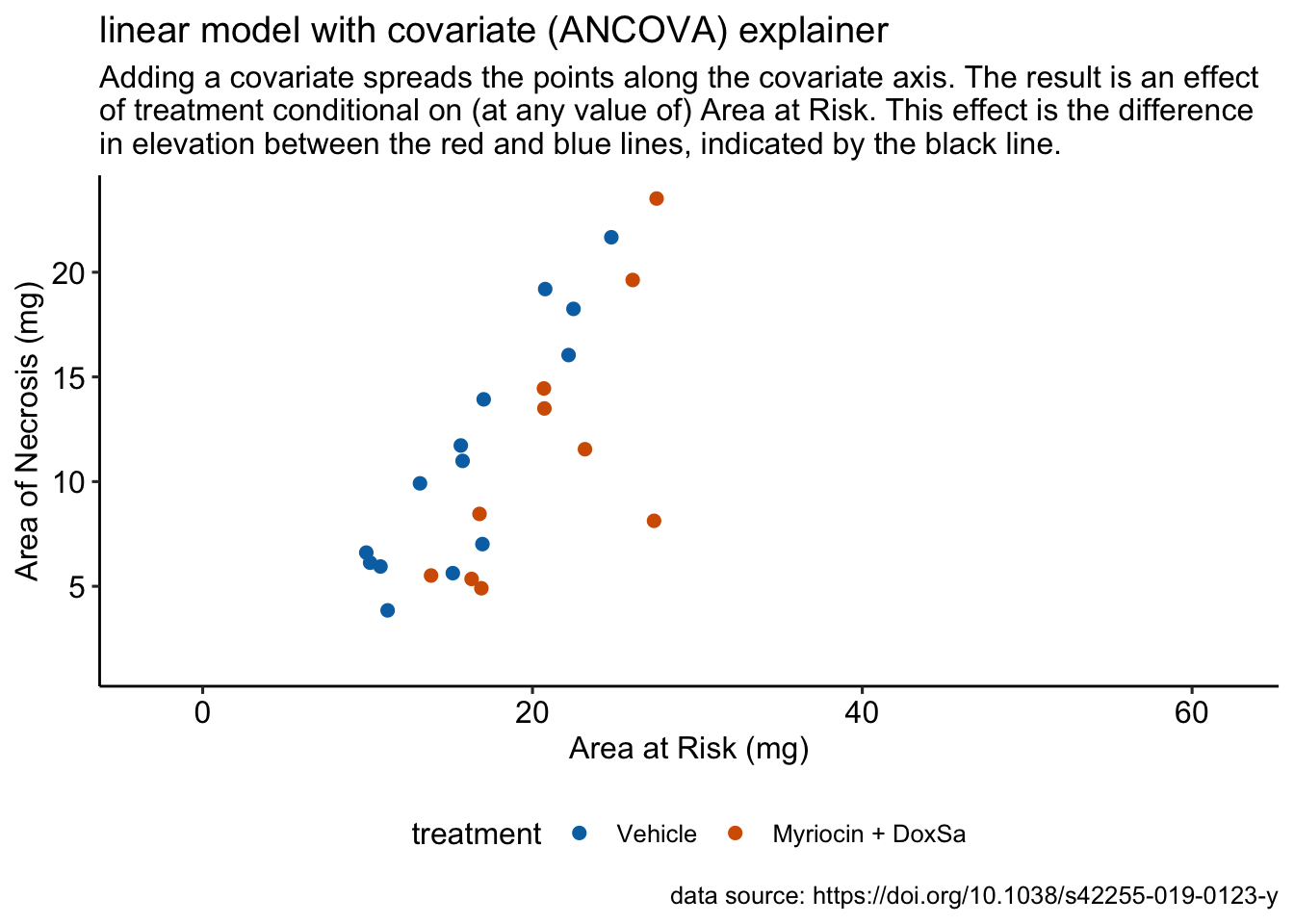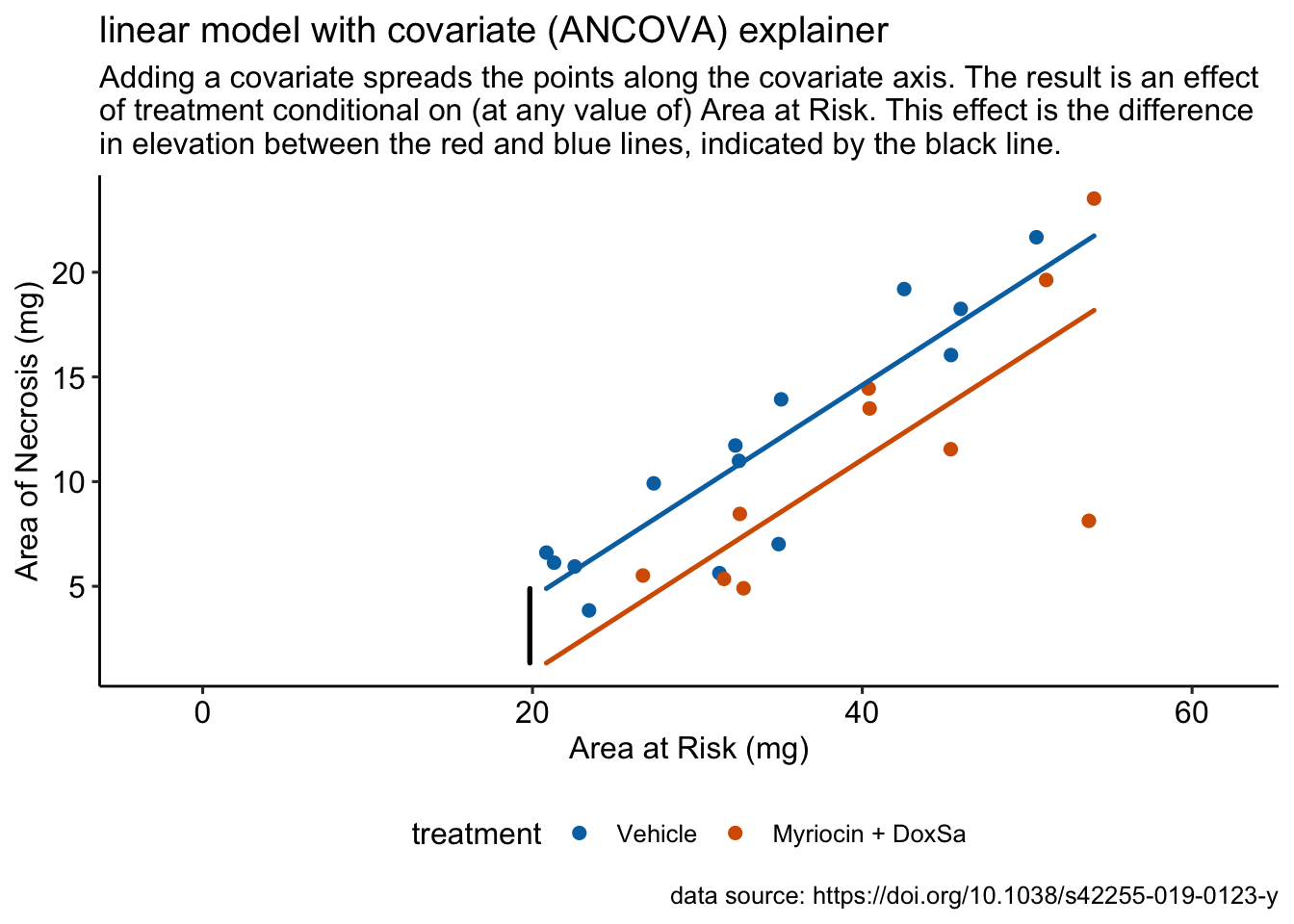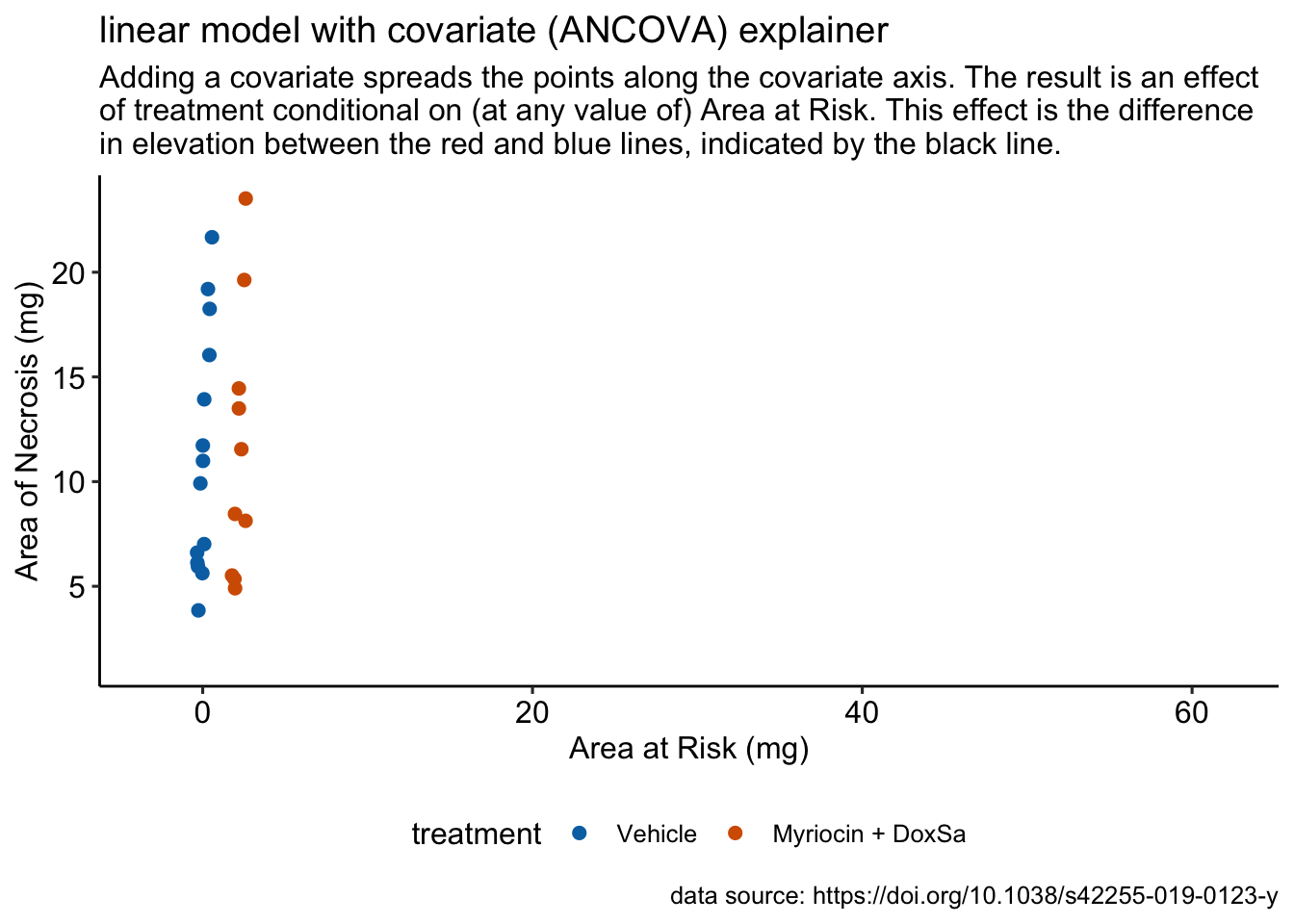
R doodles. Some ecology. Some physiology. Much fake data.
Thoughts on R, statistical best practices, and teaching applied statistics to Biology majors.
Jeff Walker, Professor of Biological Sciences
University of Southern Maine, Portland, Maine, United States